
空気圧で駆動するゴム製の人工筋(ラバチュエータ,ブリヂストン)は, 小型,軽量,高出力,滑らかな動き,可変粘弾性,安全,安価 などの優れた特徴をもっています. この反面,空気圧伝達による大きな時間遅れ(むだ時間)や非線形性(ヒステリシスなど)などの要因により,一般的なフィードバック制御では制御できません. しかし,ヒトの上達する情報処理メカニズムを模倣した運動学習モデルを用いることにより,学習後には,ロボットアームの柔らかさ(粘弾性)を調節することにより,巧みな運動が可能となります.この学習は下記のフィードバック誤差学習法を用いています.
<応用例>フィードバック誤差学習
 フィードバック制御(従来手法):右図は単純なフィードバック制御です.フィードバック制御でうまく制御できる場合には問題ないのですが,フィードバック制御ではうまく制御できない場合があります.
フィードバック制御だけではうまくいかない場合,下記で説明するようなフィードバック誤差学習法により対処することができます.
フィードバック制御(従来手法):右図は単純なフィードバック制御です.フィードバック制御でうまく制御できる場合には問題ないのですが,フィードバック制御ではうまく制御できない場合があります.
フィードバック制御だけではうまくいかない場合,下記で説明するようなフィードバック誤差学習法により対処することができます.
フィードバック誤差学習法:フィードバック制御器に内部モデル(神経回路モデルなど)を並列に付加し,この内部モデルをフィードバック誤差学習法により学習させることができます.この学習方法では, フィードバック制御器の出力を用いて内部モデルを学習しますので,従来より用いていたフィードバック制御をそのまま使用することができます (Kawato et al., 1987; Katayama et al., 1993, 2001, 2004, 2005).
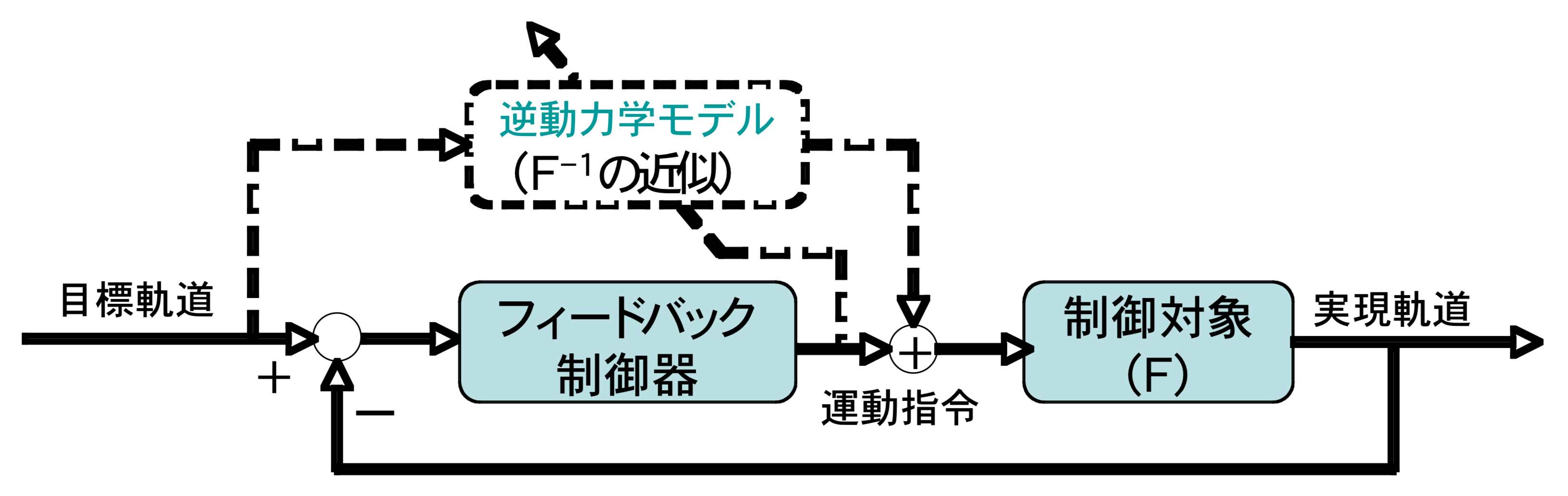 学習前:フィードバック誤差学習法では,
フィードバック制御器の出力を用いて内部モデルを学習しますので,内部モデルの学習前にはフィードバック制御主体で制御されます.
学習前:フィードバック誤差学習法では,
フィードバック制御器の出力を用いて内部モデルを学習しますので,内部モデルの学習前にはフィードバック制御主体で制御されます.
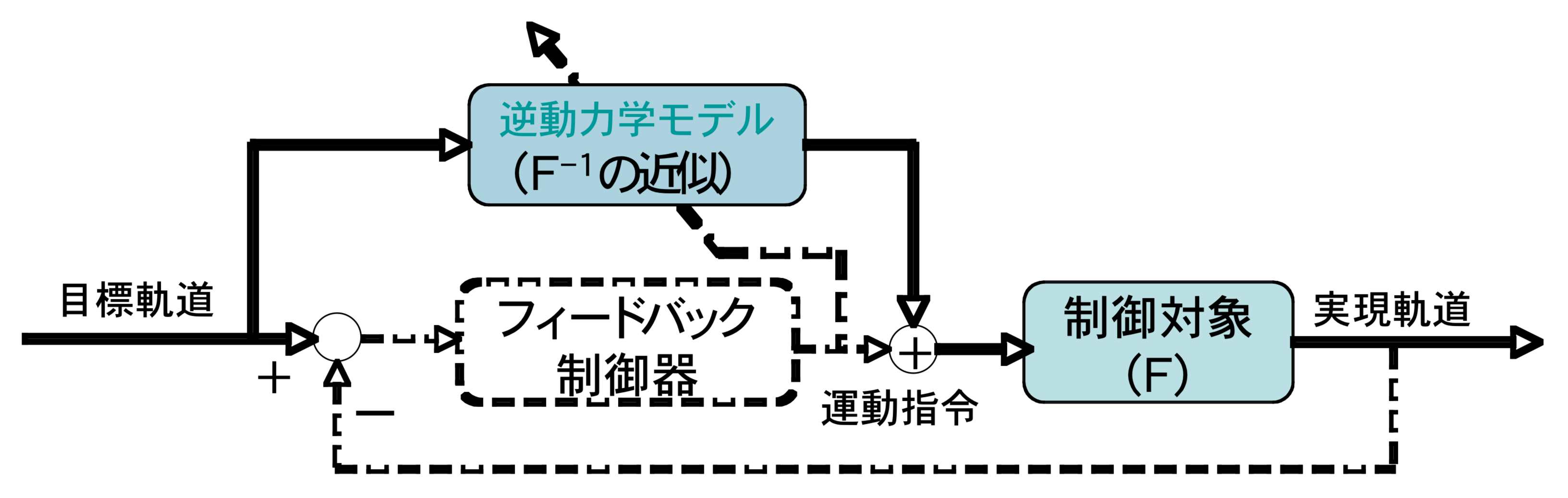 学習後:学習が進むにつれて内部モデルの出力が徐々に大きくなり,逆にフィードバック制御器の出力は徐々に小さくなります.このため,学習後には内部モデルの出力を用いた制御(フィードフォワード制御)に移行します.
このため,高精度な制御か実現されます.
学習後:学習が進むにつれて内部モデルの出力が徐々に大きくなり,逆にフィードバック制御器の出力は徐々に小さくなります.このため,学習後には内部モデルの出力を用いた制御(フィードフォワード制御)に移行します.
このため,高精度な制御か実現されます.
学習後の内部モデルの入出力関係は,制御対象の入力と出力を逆にした関係になっています.制御対象を関数Fとすると,内部モデルはその逆関数F -1となります.このため,この内部モデルを逆動力学モデルと呼んでいます.
利点:
・フィードバック制御から容易に移行できる.
・フィードバック制御の性能を改善することができる.